相信用过Java的都对解释执行这个名词不陌生,但是可能大多数人都不能理解解释执行的意义,以及虚拟机为什么采用解释执行的方式,有什么利弊,它是如何被执行的。本篇博文标题是基于栈的解释执行引擎,那么我们可以直观理解,解释执行操作的是栈,栈存在于虚拟机内存中,频繁的入栈出栈都是对内存的频繁读写,这也是Java在性能上较之C++等编译执行语言所不足的地方,对内存的读写操作较寄存器总是低效。
解释执行
解释执行是相对编译执行的一个概念,类比java和c++,解释执行基于字节码,编译执行相对于汇编指令。字节码指令只要相应的解释器都能识别,不依赖于CPU寄存器结构和操作系统,汇编指令则是基于CPU寄存器的操作指令,不同的操作系统会根据CPU的不同导致编译不同的结果。这也是java能跨平台而c++不能跨平台的原因,因为不同的操作系统对硬件的适配不同,所以linux和windows系统对c++等编译执行的语言都有不同的编译器,windows上可执行的程序在linux上是无法执行的。
Java字节码在执行的解释执行的过程中不依赖于CPU寄存器结构,不代表不会利用寄存器优化执行性能。因为现代计算机的缓存结构是金子塔尖形状,寄存器的读写性能是最优也是最昂贵的,所以Java会把频繁访问的操作数栈顶元素优化缓存的到寄存器中。
基于栈的指令集和基于寄存器的指令集
栈指令集的优点:
- 可移植,寄存器由CPU直接提供不受型号限制,虚拟机可以自行利用寄存器优化性能。
- 代码相对紧凑,字节码中每个字节代表一个指令。
- 编译器实现简单,不用考虑分配空间,都在栈上进行操作。
栈指令集的缺点:
- 栈指令集数量较寄存器指令集数量更多。
- 栈指令集操作内存执行速度更慢。
基于栈的解释器执行过程
这里以一段四则运算的代码为例,演示解释器执行字节码的过程。1
2
3
4
5
6public int test(){
int a=100;
int b=200;
int c=300;
return (a+b)*c;
}
通过javap -v test.class查看解释编译之后的字节码指令:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23{
public int test();
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: bipush 100
2: istore_1
3: sipush 200
6: istore_2
7: sipush 300
10: istore_3
11: iload_1
12: iload_2
13: iadd
14: iload_3
15: imul
16: ireturn
LineNumberTable:
line 8: 0
line 9: 3
line 10: 7
line 11: 11
}
观察Code部分显示栈深度为2,局部变量表为4个Slot大小,下面演示这段字节码是如何被解释执行的。
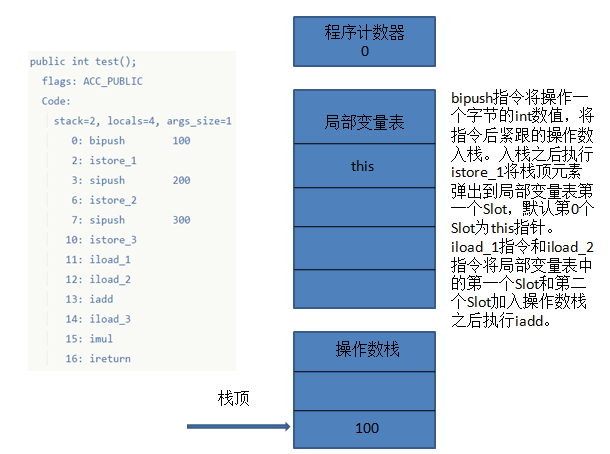
这里需要着重解释的一个概念是,虽然虚拟机栈的栈帧在执行过程中局部变量表充当了变量拷贝的角色,有些书上会将堆栈结构类比java并发工作内存和主内存。实际上这里的局部变量表只是在栈中的一份变量拷贝,生命周期是栈帧的生命周期,工作内存是基于高速缓存和主内存这样的缓存结构的,会从一级缓冲向主内存不断会写。如果说强行要将栈类比到工作内存,实际上字节码在执行过程中需要利用现代高速缓存结构这样的概念模型可以类比,如写对象属性操作。
总结
本篇并没有过多强调和介绍所有的字节码指令,而是展示了字节码指令在执行过程中的几个重要部分,希望读者有一个概念模型上的理解,实际上虚拟机在指令生成过程中会进行很多优化。本文也是解决了我在阅读java并发内存模型中的一些困惑,堆栈模型和java并发内存模型存在本质上的区别,不能完全进行类比,对CAS原子操作的理解也更加深刻。