在阅读源码的过程中,发现很多地方会使用到位操作来提高计算的效率。我们很常见的取模操作,在源码中都会通过与操作来完成。了解和灵活运用位运算可以帮助我们快速理解源码,写出较为简洁的代码。
位操作运算符
针对二进制位操作运算符主要包括:
- 与操作(&),1&1才为1,其它都为0.
- 非操作(~),简单取反.
- 或操作(|),当两边操作数的位有一边为1时,结果为1,否则为0.
- 异或操作(^),参与运算的两个值,如果两个相应位相同,则结果为0,否则为1.
二进制位移动运算符:
- 有符号的右移位运算符(>>),使指定值的所有位都向右移规定的次数.正数在高位插入0,负数则在高位插入1. 右移一位相当于除2, 右移n位相当于除以2的n次方.
- 有符号的左移动运算符(<<),使指定值的所有位都向左移规定的次数, 丢弃最高位, 在低位补0. 在数字没有溢出的前提下,对于正数和负数, 左移一位都相当于乘以2的1次方, 左移n位就相当于乘以2的n次方.
- 无符号的右移位运算符(>>>),忽略了符号位扩展,无论正负,都在高位插入0.
位操作的应用
取模操作
这里截取一段hash算法根据hashcode得到映射桶的代码:
1 | /** |
hashmap在插入元素的时候会首先根据hashcode确定映射到某个桶,注释处采用的操作:
1 | (n - 1) & hash |
相当于操作:
1 | hash % (n - 1) |
这里需要注意的是,hash在扩容的都是以2的整数倍进行扩容,也就是为什么hashmap的数组长度要取2的整数次幂。因为这样(数组长度减1)正好相当于一个”低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值。以初始长度16为例,16-1=15。二进制表示为00000000 00000000 00001111。这样和某散列值进行与操作的结果如下,截取了最低的四位值,完成了取模的操作:
1 | 10100101 11000100 00100101 |
当然二进制&的计算效率是要远远大于十进制%的计算效率。
交换数字
一般进行数字交换的操作我们会定义一个中间变量,作为交换的中转站。如果通过异或操作来进行可以省略中间变量的操作。
1 | public class Demo3 { |
输出:
1 | a: 666 b 100 |
数a两次异或同一个数b(a=a^b^b)仍然为原值.
HashMap扰动函数
这里我们分析一段HashMap的源码:
1 | /** |
这里是桶映射的方法函数,针对上面取模操作的介绍,为什么还要对hashcode进行一个这样操作,为什么不直接进行散列?
这里想象一下hashcode是一个32位数,只保留最后几位的取模操作,碰撞是会相当严重的。而且我们在设计hashcode的时候不能保证是规律分布,很有可能在呈四位的跳跃状,那么很有可能会造成严重的碰撞。这样的话就很蛋疼了,这样的散列是没有任何价值的。那么我们就需要进行高低位的扰动:
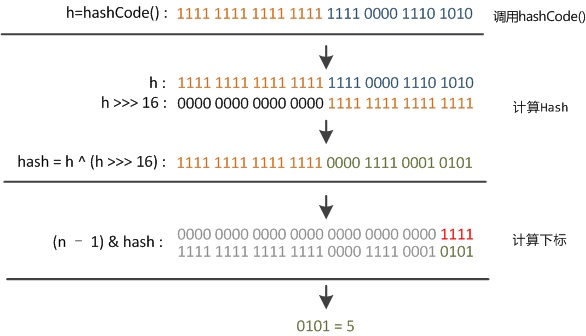
右移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始hash码的高位和低位这样来加大低位的随机性。从而减少碰撞的概率。实验显示,当hashmap数组的长度为512的时候好,也就是用掩码取低9位的时候,在没有扰动函数的情况下发生了103次碰撞,接近百分之三十。在使用了扰动函数之后只有92次碰撞。碰撞减少了将近百分之十。
Java8只做了一次扰动,一般也可以考虑做多次的扰动,但是可能考虑到效率原因改成了一次。
INT十进制转换为二进制
做一段测试代码的小记录:
1 | /** |
总结
本文主要解决自己在阅读HashMap源码过程中碰到的一些疑惑,进行记录,接下来将会介绍HashMap相关的源码实现。