###
索引的几种数据模型
数据库引擎在设计索引结构的时候首先需要数据结构,怎样的数据结构能够兼容查询和更新,在不同的场景下选择也有所不同。下面主要介绍几种模型以及数据结构上的利弊。
哈希索引
哈希索引数据模型类似HashMap,KV结构,通过数组+链表的方式去存储。利于等值查询(单值查询),不利于多值查询(范围查询),利于更新。
应用:主要是应用在memcache,nosql等。主要为单值查询比较多的场景,更新性能也不差,不考虑IO。
有序数组索引
有序数组数据模型类比数组,有序的记录。利于查询(单值查询和多值查询表现都比较优秀),复杂度O(log n),不利于更新(需要移动位置)。
应用:有序数组索引只适用于静态存储引擎,比如你要保存的是某一年某个城市所有的人口信息。多为查询,更新比较少。
N叉树索引
N叉树索引数据模型,类比mysql中的B+TREE。利于IO,查询和更新的表现比较平衡。数据库数据存储在磁盘,多叉树可以减少大量IO。
应用:mysql innodb采用的b+tree,相较于我们通常看到的平衡二叉树(查询O(log n),更新O(log n))兼容了磁盘IO,在大数据存储查询上更有优势。
innodb的索引模型
innodb采用b+tree维护每个索引,每个索引对应的都是一个b+tree多叉树的数据结构,其中mysql会为每个表默认生成一个字自增的primary key,作为表的唯一主键。那么我们将mysql的索引类型可以简单的分为主键索引的普通索引。
主键索引
mysql的主键索引我们又可以称之为聚簇索引,索引叶子结点记录了所有的字段信息。
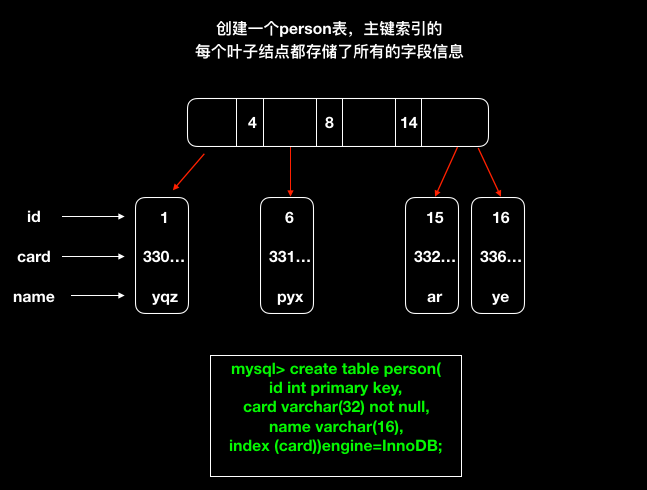
普通索引
普通索引只存储了索引的值+主键的值。普通索引查询之后,如果需要取出主键之外的信息,只要索引中不包含,就需要进行一个“回表”的操作。这里衍生出一种索引,叫做覆盖索引,意思是不需要回表,所查询的信息已经在普通索引中维护好了。例如我们上面建立的person表,card这个字段上是有一个普通索引的。
1 | select id from person where card='330...';//覆盖索引(不会进行回表) |
1 | select * from person where card='330...';//用不到覆盖索引(找到id后回表,在主键索引中再执行一次查询) |
覆盖索引
覆盖索引,上面的表中,我们如果根据单个字段的值建立索引,在根据索引遍历到记录之后需要进行回表操作。那么如果我们加索引index(name,card),数据在根据身份证去找名字的时候的查询语句就不需要回表,这个就叫覆盖索引。
可以看到覆盖索引其实也就是在我们通常称为联合索引的基础之上的。联合索引会导致一些失效的情况:
普通索引和唯一索引如何选择
两种索引的选择主要基于性能,从读和写考虑,普通索引的读和唯一索引的读性能差别基本不大。
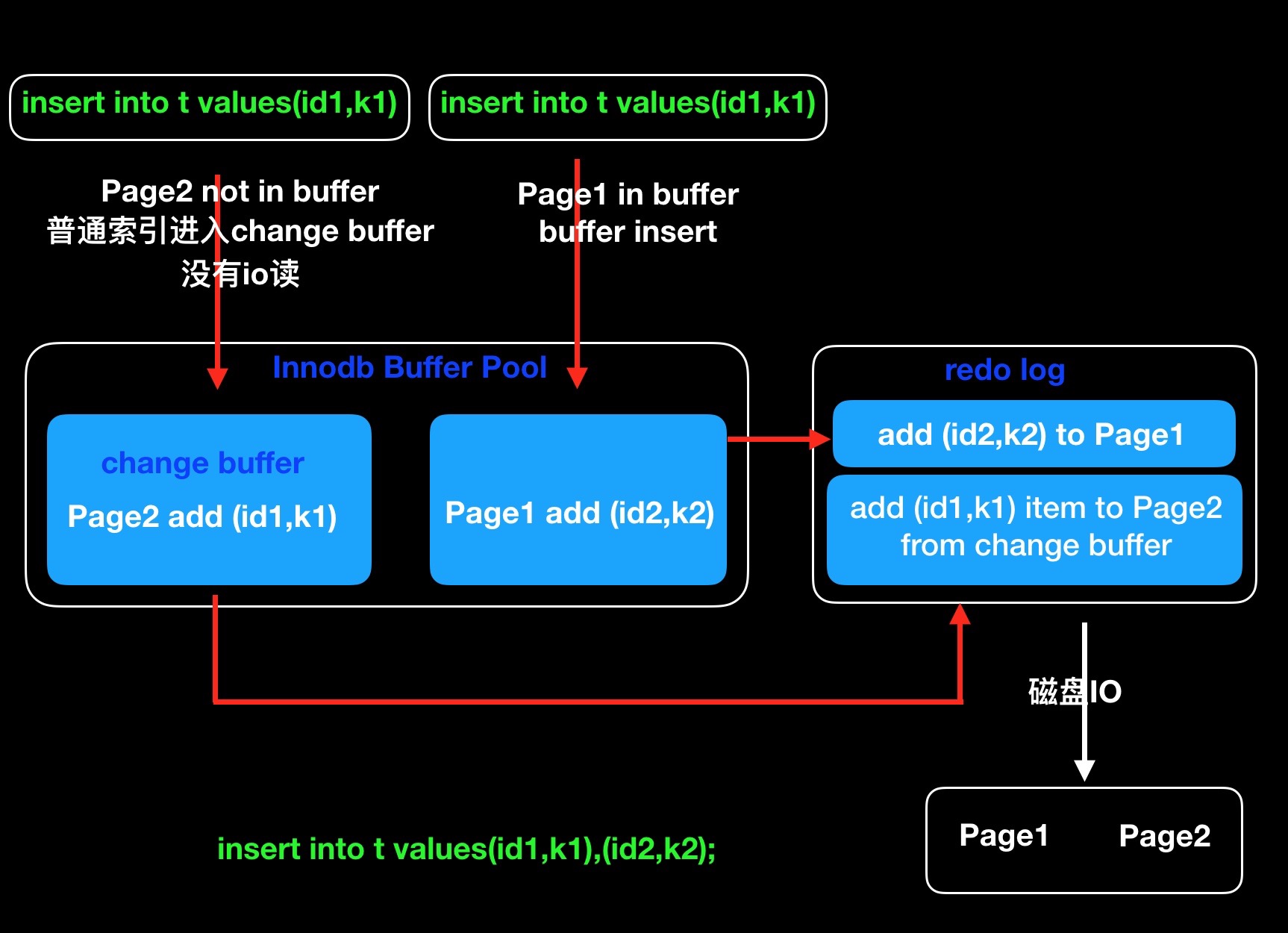
普通索引不需要唯一约束校验,可以将更新语句存储到change buffer中,等到记录被读取的时候再直接更新内存记录,这样节省了一次随机读IO。尽量选择普通索引,能够改善更新效率。
redo log 和 change buffer
1.change buffer 在innodb的内存中,redo log是日志文件。
2.change buffer主要为了优化随机读,redo log主要优化随机写*(批量写入减少IO)。
in查询优化
业务表retail_order假设我们建立一个索引,索引sql如下:
1 | alter table retail_order add index idx_type_code(business_type,order_code); |
1 | retail_order 1 idx_type_code 1 business_type A 1 NULL NULL BTREE |
采用union all(不区分重复记录):
1 | (SELECT * |
分析explain 和 慢查询日志:
1 | # Time: 2019-01-14T07:58:52.068234Z |
理论上用in查询会使索引失效,但是实际这里我们通过in查询在先前的索引基础上优化器是有做优化的,并且减少了数据库的扫描行数。这里暂时不知道如何做的这个优化。
1 | explain select * from retail_order where business_type in ('CUSTOMIZED_CAR','COMMON_NEW_RETAIL') order by order_code limit 100; |
1 | -- explain result 扫描行数195行,做了优化 |
对比发现,sql优化器有对这种情况的in查询做优化,实际上还是用到了索引。注意这里的耗时比较长主要因为传输的数据量比较大。
查看索引和库文件大小
1 | -- 库文件和索引大小存在information_schema库中的TABLES表 |
1 | 216.96MB |
查看线上的索引文件大小:
1 | use information_schema; |
1 | 16.97GB |