当mysql单表的数据量达到200万条以上时,建立索引和单表查询的代价较大,查询性能也会到达瓶颈,需要进行分库分表。
垂直拆分+水平拆分
垂直拆分(单表字段过多):将单表的数据量分别分散到多个库表,拆分的主要标准是热点数据vs非热点数据,热点数据mysql有buffer_pool缓存热点数据页。分别将热点字段拆分到热点表,非热点数据拆分到非热点表。
水平拆分(单表数据记录过多):将单表大量的数据分散到多个库表,表结构一直,利用数据库中间件分发到对应的库。业务上当单表的数据过多时,采用读写分离无法改善单库的性能瓶颈。分散到多个库表直接提高性能。
水平拆分一般采用下面的两种方式:
- 按照范围range拆分,例如根据创建时间将1000w条记录分散到五个表,优点是简单,当新数据来的时候不需要改表结构,只需要不断进行拆分就行。确定是一般最近的数据都是热点数据,导致查询都落在一个库表,导致分库分表并不是很彻底。
- 按照hash的方式来拆分,每一条记录的主键都对应一个hash值,映射到不同的库表,优点是数据分散较为均匀,查询压力分散,并发承载力更好。缺点是如果需要再次扩展库表,需要对所有的数据重新进行hash分配库表,代价较大。
数据库(分库分表)中间件
这里主要罗列两种目前用的比较多比较主流的中间件,一种是基于客户端的sharding-jdbc,一种是基于proxy代理的mycat。
mycat优点是proxy有单独的团队维护升级,业务团队客户端不需要关心,适用于大规模公司(阿里面试问了好几次分库分表)。
sharding-jdbc是基于客户端的模式,缺点是需要客户端主动进行版本的升级,优点是不需要团队专门维护,适用于中小规模公司。
分库分表数据迁移
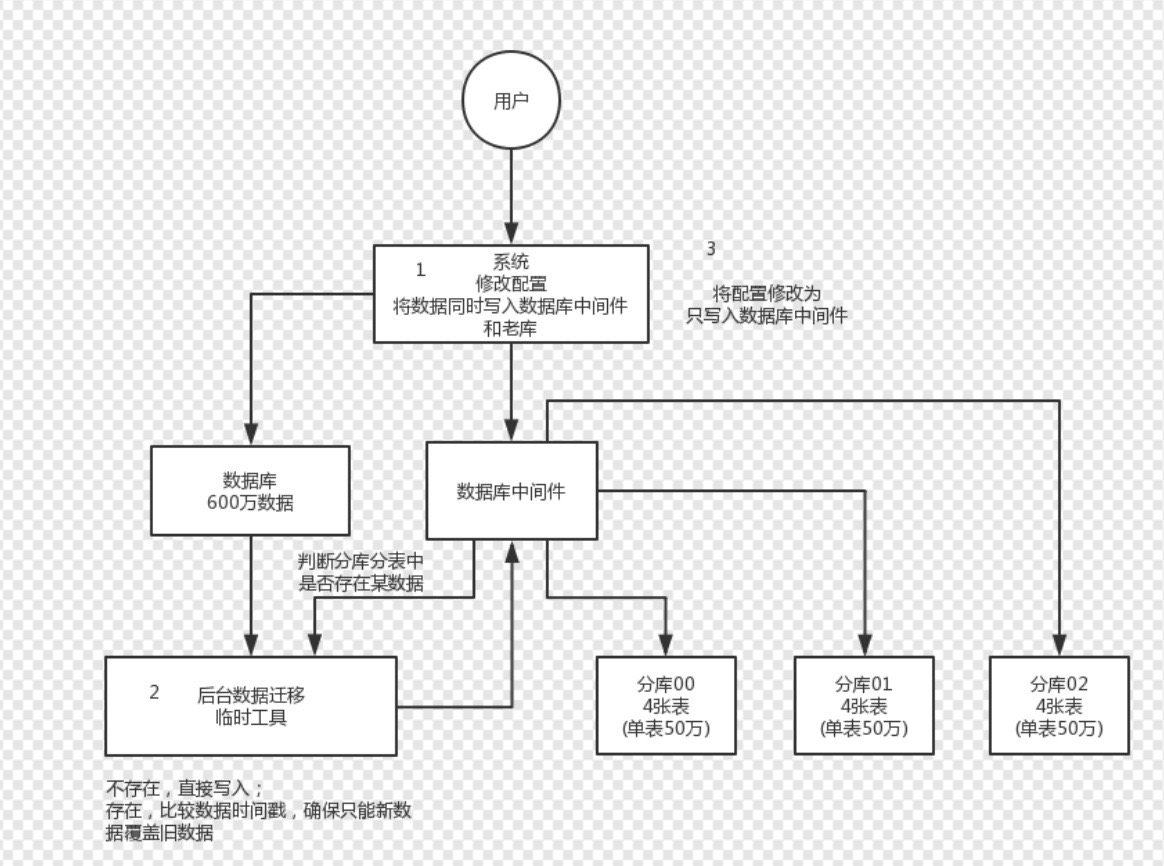
实际场景中,未分库分表状态需要支持动态切换到分库分表状态,但是后台在升级或者优化的过程中需要尽量考虑到是否对业务产生影响,如果通过停机升级的方式大部分场景下是不可以接受的,这里介绍一种双写迁移方案。
- 1.业务团队改写配置,对于增删改操作,同时落到老数据库+分库分表数据库中间件。查询操作依旧走老数据库。
- 2.开始从老数据库导入数据到数据库中间件,覆盖原则为新数据覆盖老数据根据最新更新时间date_update来判断。
- 3.确保数据全部导入完成,业务方配置全部切换到分库分表数据库中间件。
动态扩容缩容分库分表方案
真实场景下对数据库做分库分表之后可能还会面临扩容的情况,需要最大程度上支持可扩展,先生成一个32*32足够使用的逻辑表,当需要扩容的时候进行动态扩容。动态扩容缩容分库分表方案步骤:
- 设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32库 * 32表,对于大部分公司来说,可能几年都够了。
- 路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,装好 mysql,呈倍数扩容,4 台服务器,扩到 8 台服务器,再到 16 台服务器。
- 由 dba 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
- 我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
- 重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。
主键id如何设计
分库分表有一个问题就是自增id如何生成,唯一主键id再分布式的情况下如何生成,介绍几种方法的利弊:
| 走单库生成主键id | 比较简单 | 单库生成无用数据,并发承载量为单库承载量,违背分库分表的初衷 |
|---|---|---|
| 数据库sequence字段分段自增 | 简单,分为32个模块32个表,每个表自增分别从id+1024累加 | 缺点是没办法进行扩展 |
| UUID生成唯一主键 | 优点是业务方自动生成,方便 | 确定是这样生成比较占用空间,字符串太长 |
| snowflake 算法 | 推荐 | 推荐 |
snowflake 算法
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的,用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。
- 1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
- 41 bit:表示的是时间戳,单位是毫秒。41 bit 可以表示的数字多达
2^41 - 1,也就是可以标识2^41 - 1个毫秒值,换算成年就是表示69年的时间。 - 10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10台机器上哪,也就是1024台机器。但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表
2^5个机房(32个机房),每个机房里可以代表2^5个机器(32台机器)。 - 12 bit:这个是用来记录同一个毫秒内产生的不同 id,12 bit 可以代表的最大正整数是
2^12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
1 | 0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000 |
总结
中间件是如何进行分库分表适配的?不管是基于proxy还是基于客户端,对客户端的查询来说,都不需要关心最终查询落到了哪个库表上,中间件会帮你全部封装好。我的理解是垂直拆分和两种水平拆分的方式,中间件会帮你维护一个映射表,某个对应的key具体映射到哪个库哪个表,然后进行统一的提交。