mysql在读写分离的场景下,可能是一主一从,一主都从。但是在实际应用场景中需要解决一个重要的问题就是“过期读”。本篇主要介读写分离可能的架构方式以及如何解决该问题。
强制从主库读取
及时查询vs非及时查询
针对某些必须保证正确读的场景,我们可以设置这个请求只能走主库,例如一个场景,商家在发布了商品之后需要立即看到商品的信息,那么这个我们可以直接从主库去读。同样的场景,买家在前端去看新发布的商品时可能并不需要这么及时,可以容忍有一定时间的延迟,那么这个查询比较适合走从库。这里我们将查询分为两类:及时查询和非及时查询。
- 优点:逻辑上比较简单,易于实现和区分
- 缺点:可能会面临所有的查询都是及时查询的情况,例如一些金融系统对及时性要求很高。
及时查询优化
即使是刚才讲到的可能面对的及时查询的情况,查询的时效性很高。为了减少主库的查询压力,我们可以让前端直接去跳转,看起来做了查询但是实际上没有查询。上架了商品之后直接将上架的商品信息展示在商品栏,减少了一次查询主库的压力。
实际上我们在应用中经常会采取强制从主库读取这种方式,但是很可能面对尴尬的场景。整个系统对时效性要求都比较高的时候,而又必须通过读写分离改善的场景下,可以如何解决过期读的问题?
判断主备延迟
每次在备库执行查询请求之前,先判断下主备是否有延迟。可以通过:
1 | show slave status; |
seconds_behind_master
判断seconds_behind_master,通过show slave status可以在从库上查看到这个参数,如果seconds_behind_master
为零,可以走从库进行查询。缺点是精度比较难保证。
对比位点和GTID集合
在备库执行show slave status可以看到备库的位点和GTID集合的状态:
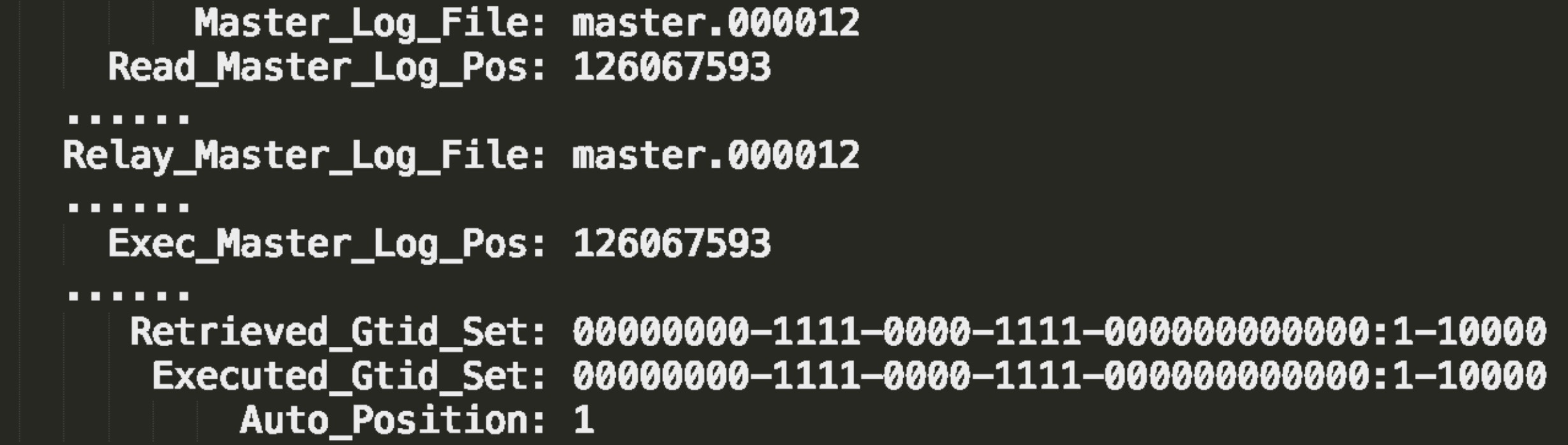
- Master_Log_File == Relay_Master_Log_File && Read_ Master_Log_Pos == Exec_Master_log_File 为true,表明备库已经完成接收到的主库的binlog同步。此为对比位点。
- Retrieved_Gtid_Set(接收到的集合) == Executed_Gtid_Set(已经执行了的集合) 为true表明备库已经完成接受到的主binlog的同步。此为对比GTID。Auto_Position=1 ,表示这对主备关系使用了 GTID协议。
虽然这种方式都可以保证备库已经执行完了主库存传过来的binlog,但是因为binlog的传送这个过程相对客户端是异步的,那么客户端在收到更新成功的一条语句之后,这个语句可能还没有传送到备库。
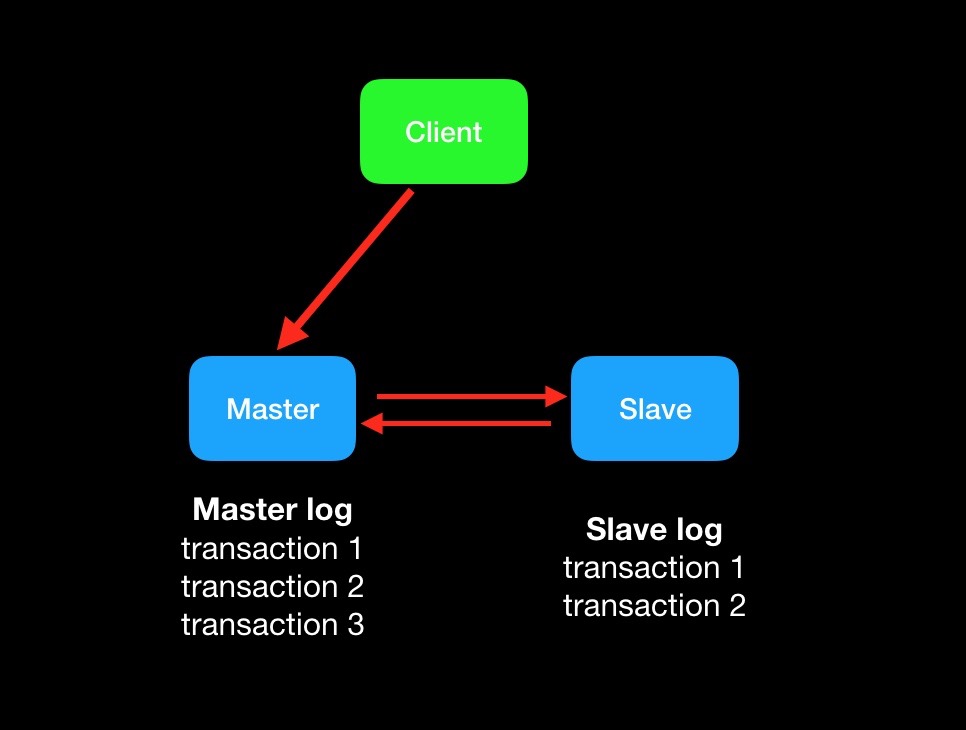
这里需要引入半同步复制semi-sync:
- 1.主库的事务提交之后,向备库发一个binlog,注意这里先不返回客户端更新成功。
- 2.备库收到binlog之后,向主库发一个ack,表示收到了这个binlog。
- 3.主库收到备库的ack之后,向客户端返回更新成功。
semi-sync缺陷:目前只能支持一主一从,如果是一主多从,并不能等待所有备库都接收到binlog,而是收到一个ack就返回给客户端。这样就不能完全保证不会出现过期读。
业务代码如何写避免过期读?
针对上节的介绍,我们可以通过判断位点和GTID集合,结合semi-sync半同步复制,判断一主多从不会出现过期读,那么在代码中如何操作实现?
等主库位点
这里需要介绍一条数据库sql指令:
1 | -- 这里file是master主库上的log文件名,pos是执行到的文件位点,timeout是超时时间 |
1.更新代码完成之后,查询请求进来,先到master执行show master status,查到file 和pos。
2.任意选择一个备库,执行select master_pos_wait(file, pos[, timeout])。
3.如果返回正整数表示该备库已经同步完成,将查询在该备库中进行否则到强制到主库中执行。
等主库GTID集合
如果数据库开启了GTID模式,这里同样介绍一个指令:
1 | -- gtid_set理解为一个字符串,不同于位点方式的是,更新操作完成之后这种方式会返回给客户端这个gtid,客户端在继续进行查询的时候只需要把这个gtid到备库进行判断。 |
1.客户端执行在主库执行更新请求,更新事务提交成功,返回给客户端gtid。
2.客户端到备库通过拿到的gtid执行select wait_for_executed_gtid_set(gtid_set, 1)。
3.返回0,表示备库中已经有执行了这个更新事务,可以进行查询。
等主库位点vs等主库GTID
相对等主库位点来说,等主库GTID方式减少了一次show master status的主库查询,对主库比较友好。但是GTID方案,如何让客户端的返回中包含事务执行的gtid?
- 需要将参数 session_track_gtids 设置为OWN_GTID,然后通过 API 接口mysql_session_track_get_first从返回包解析出 GTID 的值即可。

总结
本篇文章主要是介绍如何在数据库一主多从类似的读写分离的架构下要如何避免过期读。虽然我们发现GTID这种方式好像能够完全避免过期读,表现比较优秀,但是实际场景下我们还是多种方式混合使用。总之我们还是需要客户端去判断,当前的请求是否可以接受过期读,如果可以接受,那完全没有必要采用等待位点或者等待GTID的方案,否则无需采用。这些都需要在实际的业务场景中去检验和选择。