mysql在处理大查询的时候需要有自己的内存策略,保证不会出现OOM(Out Of Memory)内存泄漏。我们从server层面和引擎层面剖析一下内存策略。
server层处理大查询
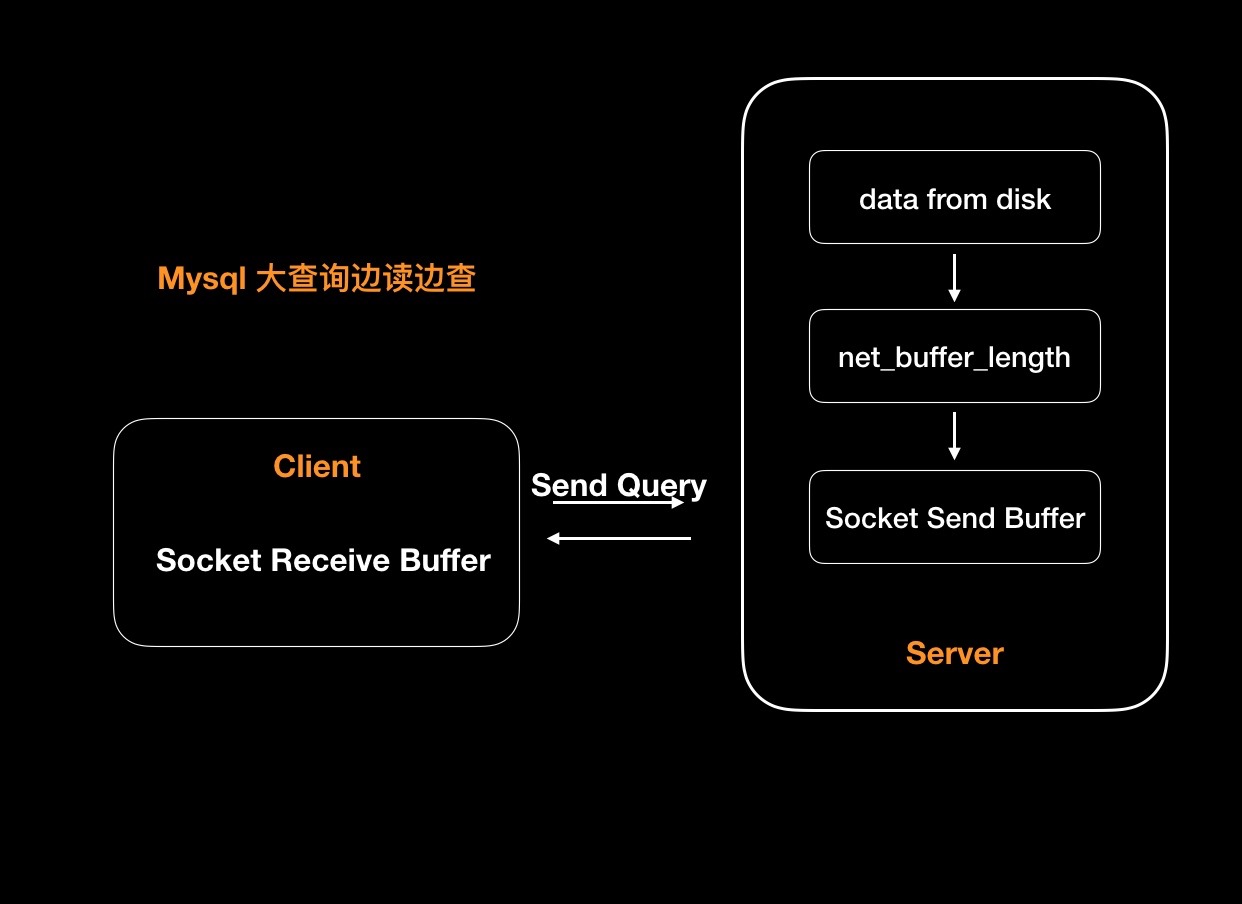
server层对大查询的处理,这里针对的大查询是返回的数据量巨大。针对这种查询server层会采用边读边发策略。也就是数据由客户端分阶段整合,服务端并不需要保证一个完整的结果集。
1 | -- 查看net_buffer_length参数,服务端会先将数据存到这个内存区域,存满之后向客户端发送,不断重复。 |
1 | -- show processlist,在大查询执行的过程中,语句会处于sending client data的状态 |
边读边发:
- 1.服务端从磁盘中读取数据加入net_buffer_length内存中。默认16k。
- 2.net_buffer_length满,触发发送到客户端操作。
- 3.收到Socket Send Buffer结果为发送成功,清空net_buffer_length,重新读取。
- 4.如果Socket Send Buffer返回EAGAIN 或 WSAEWOULDBLOCK,表示Socket Send Buffer已满,进入等待直到重新可写。
Innodb处理大查询
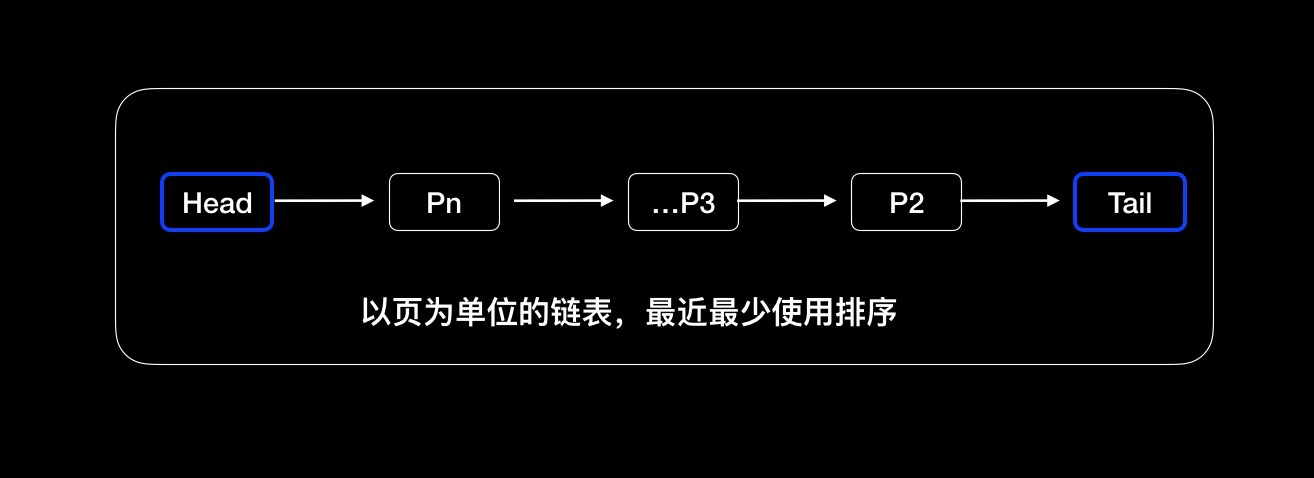
大家都知道Innodb在执行查询的之后都会将sql和对应的数据页,放置在内存中,也就是Innodb buffer pool size,这个内存区域我们之前有介绍可以通过redo log减少随机写操作,以及change buffer来减少随机读操作。但是在大查询的情况下会面对哪些问题,先看这个区域采用的LRU算法(最近最少使用算法)。
- 1.最近最少使用算法采用链表,以一个数据页为单位P1,P2…
- 2.从磁盘中读出一个页Pn会放置在链表的头部。
- 3.访问到某个数据页Px,先返回客户端结果,然后将该页放置到链表的头部。
- 4.当Innodb buffer pool size已经满了,取一个最旧的页,删除数据,存入新数据并将其放置到头部。
针对大查询的场景,如果不断查询出新的数据,单纯采用LRU算法(最近最少使用)查询出来的新页会直接替换老页,导致正常的业务内存缓存会被替换掉,增加了磁盘IO,而这些新增的缓存页在第一次使用之后又不会再进行使用。这种场景Innodb针对LRU做了分代优化,将这个buffer区域按照5:3划分为young和old区。这个概念其实在垃圾回收机制的分代收集的场景类似。针对不同的生命周期定制不同的淘汰方案。
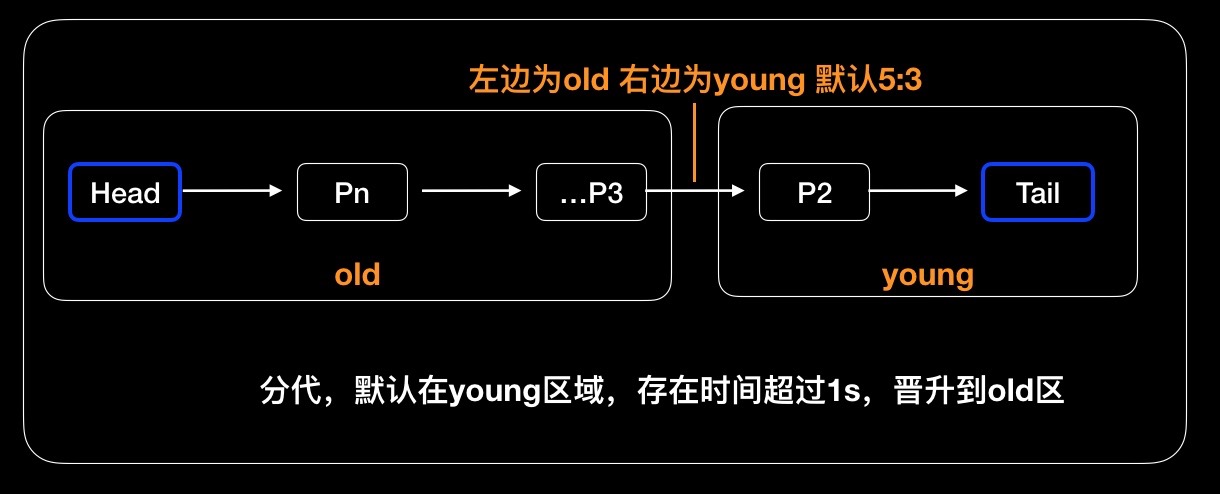
需要注意的是,分代的主要目的还是基于提高内存命中率。
总结
mysql针对大查询通过server层进行边读边写的操作防止内存泄漏,如果出现sending client data并且时间特别长的情况下,可以尝试调整net_buffer_length参数。但是还是需要通过业务这边减少查询的数据量来进行优化改善。
Innodb通过Innodb_buffer_pool_size内存来进行数据页的缓存,大查询可能导致不经常使用的数据页占领这个buffer区域导致其他的查询性能下降。LRU算法(最近最少使用)基础上的分代算法的改进可以保证正常业务和大查询业务的平衡。