线程池
线程池主要用于管理线程资源,在Java中,线程资源映射到操作系统层面,占用的是操作提供层面的资源。如果不进行良好的管理,可能会快速耗尽系统的线程资源。你可以编写多线程并行的代码,将任务提交给线程池的实例执行。线程池会管理线程的生命周期,以及会将任务维护在一个内部的队列中,完成任务的调度。
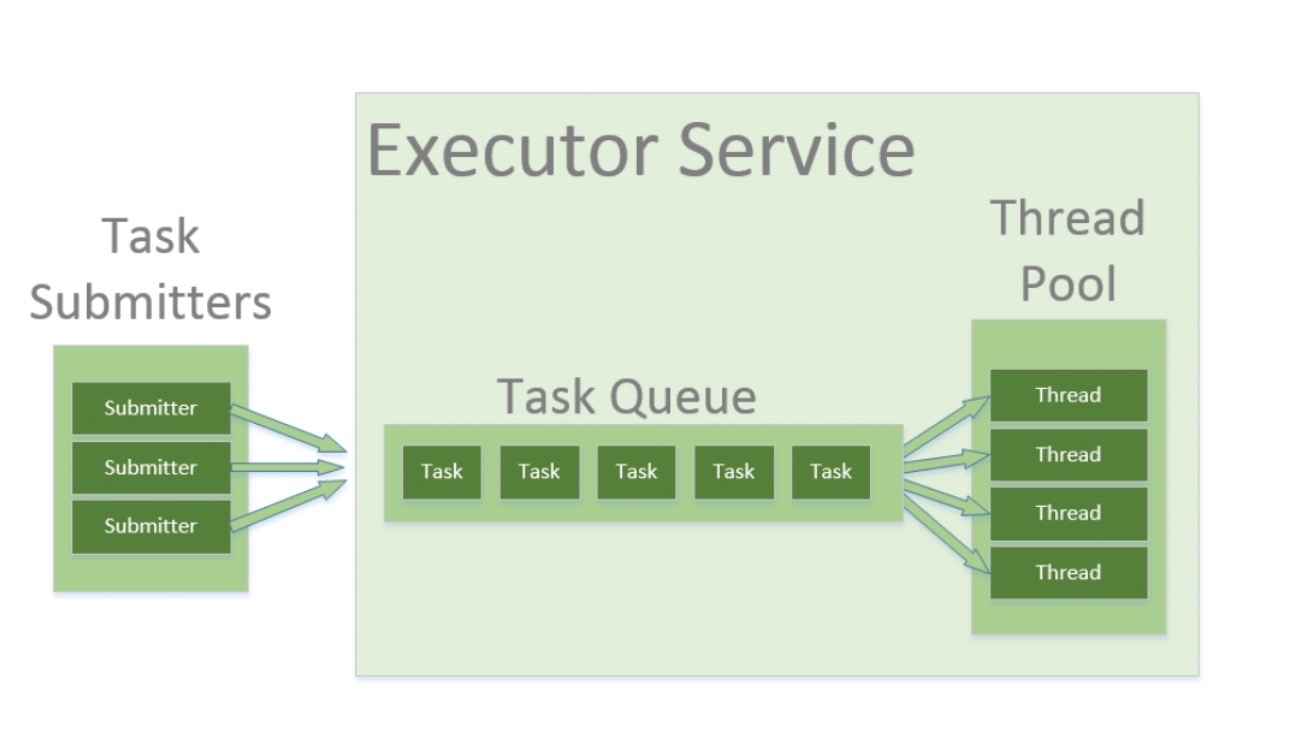
Java中的线程池
Executor+Executors+ExecutorService
我们通常会用到这几个类,其中Executors这个类可以获取到很多初始化的线程池实例,这些实例拥有不同的预配置。如果你不需要自定义一个线程池,这个类的使用会非常方便。
Executor和ExecutorService提供了一些接口方法可以让开发者自定义去实现,通过这种方式将提交任务也就是上图中的左边部分和线程池的具体实现分离开来。这里我们通过一段代码查看如果通过Executors这个线程池工具类获取一个Executor实例,然后通过这个实力去提交一个task:
1 | Executor executor = Executors.newSingleThreadExecutor(); |
Executor提供的方法较为简单,我们可以利用ExecutorService的一些更为丰富的api去开发:
1 | ExecutorService executorService = Executors.newFixedThreadPool(10); |
我们可以通过返回的Feature来等待这个异步线程任务完成。这里延伸出Java8中CompletableFeature,这个类提供的异步操作api更为丰富之后可以对比介绍,同时可以深入了解ExecutorService。
ThreadPoolExecutor
ThreadPoolExecutor是一种可扩展的提供很多参数调整的线程池,这里主要介绍几个参数,corePoolSize(核心线程数),maximumPoolSize(最大线程数),keepAliveTime(超出线程生命周期)。队列类型留到下次进行补充。
corePoolSize是线程池的核心线程数,会从队列中不断拉取任务进行执行,如果队列中有任务到来会new一个核心线程进行执行,同时如果执行队列执行完了,对应的核心线程也不会进行回收。当我们通过submit提交任务时,会首先往任务队列里面追加,直到超出队列的大小之后,会创建新的线程进行执行。maximumPoolSize指定了当任务队列存满时,可以独立创建的最大线程数,下面的例子任务队列长度为3,最大线程数为10,所以当线程数量超过5时,会生成新的线程。另外当额外需要的线程超过maximumPoolSize-corePoolSize时,那么会队列会抛出RejectedExecutionHandler异常。
1 | package com.souche; |
这里我定义了14个任务,并且每个任务都休眠10s,首先会被核心线程参数拿走2个任务,然后往LinkedBlockingDeque追加3个任务,然后最大线程参数独立生成8个线程,总共消化了13个线程,最后一个线程被队列拒绝,抛出异常,这段代码的执行结果:
1 | 当前线程池核心线程数:2 |
其中Executors类提供了两种默认可以获取ThreadExecutorPool实例的方法,可以看下一些默认的配置:
1 | /**只传入一个参数线程数 |
缓存的线程池也就是第二种,其实就是为了支持线程无限量的增长,以适应无限数量任务的添加。当时他们会被回收当空闲的时间超过了60s,这种线程池的一种很明显的应用场景就是有很多短期的任务。第三种单线程池实际上更加适合做事件的循环。
1 | AtomicInteger counter = new AtomicInteger(); |
这里补充一下队列类型queueWork吧,看了下源码中的注释,搬运一下:
- SynchronousQueue直传队列。中间不允许任何task缓存,所有的任务直接提交给核心线程,核心线程不够直接交给最大线程新起线程。通常直传队列需要无限的最大线程大小。因为每个任务过来都需要直接被线程消费。可能导致新线程不断增长超出系统负荷。
- LinkedBlockingQueue无界队列。这个队列如果不指定队列大小,将会容纳无限制的task任务,那么实际上最大线程数的参数便没有效果了,keepAlive时间也没有必要,因为不会有新的线程被开辟。这种情况可能适用于请求某一瞬间爆发,相当于消息队列缓存,但是也有可能太多完全处理不过来。可能导致队列无限增长超出内存负荷。
- ArrayBlockingQueue有界队列。这个队列可以指定大小,防止资源耗尽的情况,队列大小和最大池大小之间应该有一种平衡。使用大队列小池可以最小化cpu使用,os资源以及上下文切换,使用小队列大池可能导致cpu过于繁忙。
通过Executors.newCachedThreadPool()获取的线程池就是通过SynchronousQueue直传队列,零队列无限池,通常适用于很多的短期任务。通过Executors.newFixedThreadPool()获取的线程池是LinkedBlockingQueue无界队列,也就是零最大池无限队列,只能指定核心线程数,也可以通过Executors.newSingleThreadPool()获取到无界队列,但是只有一个消费者线程,而且不能被强制转换为ThreadPoolExecutor类型。
核心线程数什么时候被回收?
当消费者线程一直从任务队列里拿任务进行消费,最后队列为空的时候,会循环等待线程池的参数keepAliveTime时间,如果在这段时间内还是没有新的任务可以获取,线程会被销毁。当然这个默认情况下不包括核心线程数。那么核心线程什么时候进行回收?
- 通过函数allowCoreThreadTimeOut设置核心线程数在keepAliveTime时间内进行回收,不然核心线程只有在线程池被关闭的时候被回收。
线程池的拒绝策略
线程池的拒绝策略主要通过实现RejectedExecutionHandler中的rejectedExecution函数。下面主要介绍下几种拒绝策略:
- ThreadPoolExecutor.AbortPolicy,退出策略,直接抛出一个运行时异常(RejectedExecutionException)。业务有损,响应较快,保护服务器资源。
- ThreadPoolExecutor.CallerRunsPolicy,调用者运行策略,只要当前线程池不处于shutdown的状态,都将这个任务交给当前调用的线程去执行。业务无损,响应较快,服务器资源无保护。
ThreadPoolExecutor.DiscardPolicy,丢弃策略,什么都不执行,直接不管这个任务。业务有损,响应较快,保护服务器资源。
ThreadPoolExecutor.DiscardOldestPolicy,淘汰策略,淘汰任务队列中头部的一个任务,然后提交到线程池中,当然有可能再次失败再次就行重试。业务无损,响应较慢,服务器资源无保护(线程一直重试)。
其中,线程池默认的策略是退出策略,直接抛出异常的方式可以保护服务器资源,当然这样的处理方式始终是不够优雅的,我们可以通过set方法根据实际场景去选择对应的拒绝策略。值得注意的是我们可以重写RejectExecutionHandler接口自定义拒绝策略,一种更可行的方式是记录日志或者持久化到磁盘。可以自定义拒绝策略初始化线程池。
ScheduledThreadPoolExecutor
Executors.newScheduledThreadPool可以获取到一个ScheduledThreadPoolExecutor继承了ThreadPoolExecutor实现了ScheduledExecutorService接口,提供了一些控制调用时间的方法:
- schedule 方法允许在指定的延迟后执行一次任务。
- scheduleAtFixedRate方法允许在指定的初始延迟后执行任务,然后在一定时间内重复执行。period参数是在开始时间之后的每个任务的间隔时间。所以执行速率是固定的。
- scheduleWithFixedDelay方法类似于scheduleAtFixedRate,因为它重复执行给定的任务。但是执行速率可能会有所不同,具体取决于执行任何给定任务所需的时间。
1 | ScheduledExecutorService executor = Executors.newScheduledThreadPool(5); |
上面初始化了一个核心线程为5,最大线程为5,并且超出线程生命周期为0s的线程池,等待500ms之后执行任务。
1 | CountDownLatch lock = new CountDownLatch(3); |
上面等待500ms后开始执行任务,并且没100ms执行一次任务,知道所有的任务都执行完成,再执行主线程。
注意点:维护了等待队列会出现线程复用的情况,如果是直传队列也会出现线程复用的情况。
ForkJoinPool
主要用于在递归算法(分治)中,多个子任务可能产生过多的线程,造成系统资源耗尽,fork / join框架的好处是它不会为每个任务或子任务创建一个新线程。这里贴一个简单的实例:
1 | static class TreeNode { |
1 | public static class CountingTask extends RecursiveTask<Integer> { |
1 | TreeNode tree = new TreeNode(5, |
Guava中的线程池实现
Guava是一个受欢迎的Google公用类库。它有许多有用的并发类,包括几个方便的ExecutorService实现。它提供了一个MoreExecutors这个工具类去获取它实现的一些线程池实例。我们可以添加Guava的maven依赖:
1 | <dependency> |
Direct Executor and Direct Executor Service
通常我们有些情况需要当前的线程去等待另一线程执行完之后再继续执行。我们可以通过countLatchDown的方式去控制,但是还是需要自己去写代码,Guava为我们提供了线程的工具:
1 | package com.souche; |
上面的例子中,当前的主线程会等待线程池中的线程完成之后再继续执行主线程。
Runnable和Callable的区别
从api上看一个Runnable没有返回值,Callable定义了返回值,主要区别一个能在Future的get方法中捕获到异常和获取结果信息。
1 |
|
总结
在本文中,我们讨论了线程池模式及其在标准Java库和Google的Guava库中的实现。